Bibliotecas, Pacotes e Módulos
Em Python, Módulos, Pacotes e Bibliotecas são formas de organizar e reutilizar código, mas têm diferenças importantes no escopo e na funcionalidade.
Módulo é um único arquivo Python (.py) que pode conter definições de funções, classes, variáveis e código executável.Serve para organizar o código em unidades menores e reutilizáveis. Python já vem com vários módulos embutido, como math, random e os.
Pacote é uma coleção de módulos organizados em um diretório. Ele deve conter um arquivo especial chamado __init__.py, que identifica o diretório como um pacote e pode (ou não) conter um código de inicialização para o pacote. É uma maneira simples de utilizar códigos de outros desenvolvedores.
Biblioteca é uma coleção de módulos e pacotes que fornecem funcionalidades para resolver problemas específicos, ou seja, com um propósito mais amplo. Pode incluir centenas de módulos e pacotes. exemplo de bibliotecas: NumPy: biblioteca para computação numérica. Pandas: análise de dados. Matplotlib: visualização de gráficos.
Principais diferenças
| Aspecto | Módulo | Pacote | Biblioteca |
|---|---|---|---|
| Definição | Arquivo único .py. |
Diretório contendo vários módulos e __init__.py. |
Coleção de módulos e pacotes para uma finalidade específica. |
| Escopo | Código pequeno e focado. | Organização maior e hierárquica. | Solução completa para um domínio (ex.: IA, dados). |
| Exemplo | math, os. |
os.path, numpy.linalg. |
NumPy, Pandas, Django. |
| Distribuição | Geralmente único e pequeno. | Vem como parte de um conjunto maior. | Normalmente instalado via pip. |
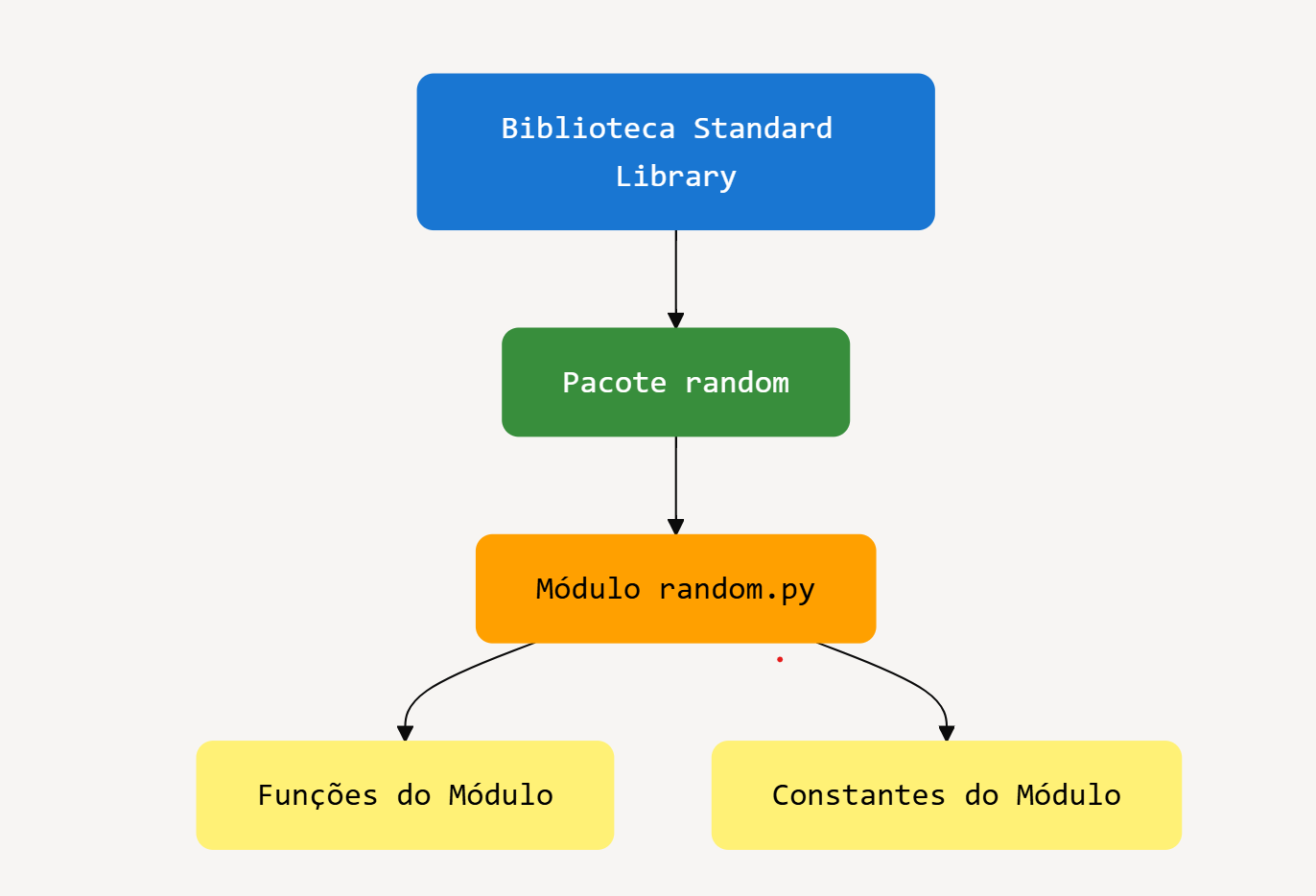
O modulo random também é um pacote devido a sua organização dentro da biblioteca padrão.
Submódulos são partes de um módulo maior. Eles permitem organizar o código em partes menores e mais estruturadas dentro de um pacote.

Verificar todos os módulos Python
No console python dê o comando:
$ help("modules")Instalar Bibliotecas Externas
Para instalar bibliotecas que não fazem parte do Python padrão, usa-se o comando pip. Ao instalar um pacote ele fica disponivel para uso global (ou da venv) por seus arquivos do projeto, sendo possivel fazer o import. O site-packages é a pasta dentro da sua virtualenv onde o pip instala todos os pacotes Python. Ao instalar os pacotes dos arquivos setup.py ou pyproject.toml(como abaixo), o pip lê esse arquivo para saber: Nome do pacote. Versão, Dependências, Scripts de console e etc e copia esses arquivos para o site-packages.
Usando a opção -e (editable ou modo de desenvolvimento), o pip não faz exatamente uma cópia, ele cria um link (symlink) para ficar redirecionando para seu pacote, assim qualquer edição é refletida na hora.
$ pip install nome_da_biblioteca
$ pip install biblioteca1 biblioteca2 --upgrade # instala e/ou atualiza varias bibliotecas
$ pip install . # instala os pacotes do projeto descritos em pyproject.toml ou setup.py (mais antigo)
$ pip install -e . # instala em modo de desenvolvimento (cria links)Importações
Módulos, pacotes e bibliotecas em Python são importados de forma semelhante, mas com algumas diferenças dependendo da estrutura e da hierarquia do pacote. para importa não se usa a extensão do arquivo, .py
Importação seletiva, é o ato de importar apenas funções, variáveis, classes (dentre outras) específicas. Apesar disso todo o módulo, pacote ou biblioteca ainda é carregado na memória, mas apenas o item selecionado é adicionado ao namespace do seu script, tornando o código mais legivel e menos poluído com funções que você não vai usar.
Um arquivo __init__.py é usado para inicializar pacotes em Python. Ele pode expor funcionalidades específicas do pacote ou configurar o ambiente inicial.
As importações podem ser feitas com Álias (um apelido), para facilitar usar nome grande do que foi importado.
Importações Relativas vs Importações absolutas
Importações relativas (como: from . import modulo_a dentro de modulo_b.py) só funcionam quando o módulo está sendo executado como parte de um pacote Python válido — ou seja, quando existe um __init__.py na pasta e o arquivo é executado corretamente como módulo (por exemplo: python -m pacote.modulo_b). Se você executar um arquivo diretamente com python modulo_b.py, o Python trata ele como __main__ e não reconhece a estrutura de pacotes ao redor, mesmo que haja __init__.py. Nesse caso, importações relativas falham, e você deve usar importações absolutas, como import modulo_a.
| Importação modulo
nome = "Pedro"
idade = 31
def saudacao():
return "Seja bem vindo"
def despedida():
return "Até mais"
# Importação seletiva
import sys
from modulo import nome, saudacao
print(f"{saudacao()}, {nome}")
print(sys.modules["modulo"].idade) # funciona, porque o módulo já está na memória
# Importação do modulo inteiro
import modulo
print(f"{modulo.saudacao()}, {modulo.nome}")
print(f"{modulo.despedida()}, {modulo.nome}")
# Importação como Alias
import modulo as m
print(f"{m.saudacao()}, {m.nome}")Nesse caso da importação seletiva não chamamos a função despedida() do modulo.py. Então não poderemos usar (a não ser usando a biblioteca sys). Outro caso tambem, seria usar a idade mesmo sem ter feito uma importação seletiva dela, pois o módulo inteiro sempre é carregado na memória (fica em sys.modules).
from tkinter import *
from tkinter import messageboxEste é um exemplo da importação de um sub-modulo que esta atrelado a outro modulo. Nesse caso, por mais que seja usado o *, é necessario importar o modulo especificamente. O comando from tkinter import * importa apenas os símbolos diretamente definidos no módulo principal tkinter. No entanto, alguns componentes, como messagebox, ttk (para widgets avançados) e filedialog (para caixas de diálogo de arquivos), estão em submódulos separados dentro do tkinter.
| Importação Pacote
Dado a seguinte estrutura:
meu_pacote/
├── __init__.py
├── modulo1.py
├── modulo2.py
# Função disponível diretamente ao importar o pacote
def boas_vindas():
print("Bem vindo ao pacote!")
# Opcional: Importar e expor outros módulos ou funções do pacote
from .modulo1 import saudacao
from .modulo2 import despedidaas funções saudacao e despedida também podem ser acessados diretamente ao importar o pacote inteiro
def saudacao():
return "Seja bem vindo"def despedida():
return "Até mais"import meu_pacote
# Função disponibilizada dentro de __init__.py
print(meu_pacote.saudacao())
# Função apenas disponível ao acessar o modulo inteiro
meu_pacote.boas_vindas()A importação do pacote completo não é comum. Nesse caso, apenas o que estiver no __init__.py será acessível diretamente.
from meu_pacote import modulo1
print(modulo1.saudacao())| Importação
A variavel global __name__ mostra o nome do arquivo. Mas apresenta o valor __main__ quando executado no proprio arquivo, e quando é importada por outro arquivo essa mesma variavel valerá o nome_do_arquivo onde foi declarada.
x = 15
# x será impresso em todos os arquivos que for importada
print (x)
# Abaixo será impresso se meu arquivo_1.py for executado mas não aparece caso seja importado
if __name__ == '__main__':
print("Estou no arquivo 1")
print(__name__)Quando importamos um arquivo py ele executa tudo do arquivo que não tiver verificação.
Ao executar esse arquivo teremos a saída:
15
Estou no arquivo 1
__main__
import arquivo_1
print("Estou no arquivo 2")
print(arquivo_1.__name__)Ao executar esse arquivo teremos a saída:
15 (executa o print do arquivo_1 importado)
Estou no arquivo 2
arquivo_1
Assuntos Relacionados
math, statistics e random
São módulos padrão (embutidos) no python.
O módulo math fornece funções matemáticas avançadas e constantes baseadas na biblioteca matemática da linguagem C.
O módulo random é usado para gerar números pseudoaleatórios e realizar operações aleatórias, como escolher itens de uma lista.
O módulo statistics fornece funções para cálculos estatísticos básicos, como média, mediana, moda e desvio padrão.
| Exemplos
import math
# Raiz quadrada
print(math.sqrt(16))
# Arredonda para cima
math.ceil(4.2) # Saída: 5
# Arredonda para baixa
math.floor(4.2) # Saída: 4
# Retorna o fatorial
math.factorial(4)
# Constante pi
print(math.pi)
# Seno de 90 graus
print(math.sin(math.pi / 2))import random
# Número aleatório entre 1 e 10
print(random.randint(1, 10))
lista_qualquer = ["Astra", "Celta", "Corsa"]
# Reordena as posições dos elementos na lista (aleatoriamente)
random.shuffle(lista_qualquer)
print(lista_qualquer)
# Escolhe aleatoriamente um dos valores da lista
random.choice(lista_qualquer)
# Número aleatório no intervalo de 0.0, 1.0
print(random.uniform(0, 1))import statistics
# média
statistics.mean([5,10])
# Moda - Valor que mais se repete
statistics.mode([1,2,3,4,2,5,2,6,3,6,7,2,3,6])os, pathlib e shutil
São bibliotecas (excessão ao shutil que é um módulo) embutidas, para iteração (manipulação) com arquivos e sistema operacional.
Diferenças entre Caminho Absoluto e Caminho Relativo
| Aspecto | Caminho Absoluto | Caminho Relativo |
|---|---|---|
| Definição | Localização completa a partir do diretório raiz do sistema. | Localização relativa a outro diretório base. |
| Estabilidade | Consistente em qualquer ambiente. | Pode variar com o diretório de execução. |
| Uso em Django | Recomendado para configurações importantes (MEDIA_ROOT, STATIC_ROOT). |
Raramente usado, exceto em testes ou situações simples. |
| Exemplo | /home/user/myproject/media |
media/ |
Resumo das Diferenças
| Característica | os |
pathlib |
shutil |
|---|---|---|---|
| Objetivo | Interação com o sistema operacional. | Manipulação de caminhos de forma orientada a objetos. | Operações de alto nível em arquivos/diretórios. |
| Abordagem | Baseado em strings. | Baseado em objetos Path. |
Baseado em funções específicas. |
| Tarefas comuns | Navegar e modificar sistema de arquivos. | Manipular e criar caminhos. | Copiar, mover e remover arquivos/diretórios. |
| Exemplo de uso | os.listdir(), os.remove() |
Path.cwd(), Path.mkdir() |
shutil.copy(), shutil.rmtree() |
import os
# Comandos para o terminal do sistema operacional
os.system("dir") # Windows - Lista os arquivos da pasta atual
os.system("ls") # Linux/macOS - Lista os arquivos da pasta atual
# Diretório atual do python
os.getcwd()
# Lista arquivos e diretórios da pasta atual
os.listdir()
pasta = 'Apostilas'
# Muda o diretório
os.chdir(pasta)
# Volta ao diretório anterior
os.chdir('..')
# Remove um arquivo
os.remove("arquivo.txt")
# Renomeia um arquivo
os.rename("antigo.txt", "novo.txt")
# Verifica se um arquivo ou diretório existe
print(os.path.exists("arquivo.txt"))
# Verificar tamanho de um arquivo
os.path.getsize("caminho_arquivo")
# Mostra todas as variáveis do sistema!
# É um dicionário sendo possível acessar uma das chaves. ex.: environ['PATH']
os.environBiblioteca que nos dá uma maneira mais moderna de trabalhar com caminhos.
from pathlib import Path
# Mostra o caminho absoluto e o nome do arquivo python que está em execução
print(__file__)
# Mostra a unidade raiz do HD onde o arquivo está salvo
caminho = Path(__file__)
print(caminho.anchor)
# Diretório atual
atual = Path.cwd()
print(atual)
# Diretório principal do usuário
principal = Path.home()
print(principal)
# Cria um objeto Path com o nome da pasta
path = Path('novo_diretorio')
# Retorna a pasta atual do objeto path
print(path)
# Retorna o caminho até a pasta atual
print(path.absolute())
# Retorna se o caminho é absoluto
print(path.is_absolute())
# Constrói o diretório, se não existir
path.mkdir(exist_ok=True)
# Verifica se o caminho existe
print(path.exists())
# verifica se é um arquivo
print(path.is_file())
# verifica se é um diretório
print(path.is_dir())
# Retorna um lista de todas as pastas e arquivos dentro do diretório
print(list(path.glob('*')))
print(list(path.glob('*.py'))) # Apenas arquivos .py
print(list(path.glob('**/*'))) # retorna também o conteúdo das subpastas
# Retorna a pasta que o arquivo atual está, mas serve para saber a pasta pai de cada caminho
print(Path(__file__).parent)
print(Path(__file__).parent).joinpath('outra_pasta_dentro_do_pai') # caminho de outra pasta dentro do pai
# Similar ao parent mas com índices para indicar qual parente do diretório, 0 sendo o pai,
print(Path(__file__).parents[2]) # mostra três pastas antes do pai .. , .. , ..
# É um iterador (objeto consumível por vez) que retorna um objeto path
print(list(path.iterdir())) # Converto em lista
# Itera sobre os arquivos e pastas trazendo o caminho absoluto de cada um dos arquivos
print(list(path.absolute() for p in path.iterdir()))
# construo um caminho com o path atual
path / 'Arquivos' / 'anotações.txt'
# convete o caminho relativo em absoluto e concatena em uma nova pasta
nova_pasta = Path('.').absolute() / 'meus arquivos'
arquivo = Path("exemplo.txt")
print(arquivo.name) # Nome do arquivo
print(arquivo.name.startswith('.')) # retorna um bool. começa com . (nesse caso arquivos ocultos)
print(arquivo.stem) # Nome sem extensão
print(arquivo.suffix) # Extensão do arquivo
print(arquivo.drive) # Nome do disco (sem a barra)
Path.unlink("exemplo.txt") # Apaga o arquivoNo pathlib, o operador / é sobrecarregado para concatenar caminhos de forma conveniente e multiplataforma.
Atributos mkdir():
exist_ok=True: Não gera erro se o diretório já existir. Se o diretório já existir, o método simplesmente não faz nada.exist_ok=False(padrão): Gera uma exceçãoFileExistsErrorse o diretório já existirparents=True: permite criar diretórios intermediários no caminho especificado, caso eles ainda não existam. É particularmente útil para criar estruturas de diretórios aninhadas de forma automática.
from pathlib import Path
caminho = Path('D:/dev')
print(caminho)
for item in caminho.glob('**/*'):
if item.is_file():
if item.name == 'jogo_da_velha.py':
print(item)**/ diz ao glob para procurar recursivamente em todos os subdiretórios. * corresponde a todos os arquivos e pastas dentro de cada diretório encontrado.
O módulo shutil é usado para realizar operações de alto nível no sistema de arquivos. Ele complementa o os, oferecendo funções adicionais para copiar, mover, remover arquivos e diretórios recursivamente.
import shutil
# Copiar um arquivo
shutil.copyfile("origem/arquivo.txt","destino/arquivo.txt")
# copia metadados de permissão do arquivo e se o segundo parâmetro for um diretório ele copia o arquivo para o diretório
shutil.copy("arquivo.txt", "copia_arquivo.txt")
# mesma coisa do método acima mas copia todos os metadados
shutil.copy2("arquivo.txt", "copia_arquivo.txt")
# Copiar um diretório inteiro
shutil.copytree("diretorio_origem", "diretorio_destino")
# Mover arquivos ou diretórios
shutil.move("arquivo.txt", "novo_diretorio/arquivo.txt")
# Remover um diretório inteiro
shutil.rmtree("diretorio_para_remover")
# Compactar pasta (formato zip suportado)
shutil.make_archive("nome_arquivo_compactado","formato","pasta_a_ser_compactada")
# Descompactar arquivo
shutil.unpack_archive('nome_arquivo_a_ser_descompactado','pasta_destino','zip')datetime
O módulo padrão datetime em Python fornece classes para manipular datas e horas. Ele é amplamente utilizado para trabalhar com informações de tempo, como calcular diferenças entre datas, formatação e parsing de strings de data e hora, validação das datas reais (incluido bisexto) e etc.
Principais formatações para usar com o método strftime() do datetime para formatar datas e horas:
| Formato | Descrição | Exemplo |
|---|---|---|
%Y |
Ano com 4 dígitos | 2023 |
%y |
Ano com 2 dígitos | 23 |
%m |
Mês como número de 2 dígitos | 12 |
%d |
Dia do mês (2 dígitos) | 01 |
%H |
Hora (24h) | 15 |
%I |
Hora (12h) | 03 |
%M |
Minutos (2 dígitos) | 05 |
%S |
Segundos (2 dígitos) | 09 |
%f |
Microsegundos (6 dígitos) | 123456 |
%c |
Data e hora completa (local) | Mon Dec 23 15:09:01 2023 |
%x |
Data completa (local) | 12/23/23 |
%X |
Hora completa (local) | 15:09:01 |
import datetime
# Define uma data (A M D)
data = datetime.date(2022,1,5) # pode ser com argumentos nomeados year=2022, day = 5, month=1
# Define uma hora (H M S)
hora = datetime.time(18,23,00)
# Define uma data e uma hora
data_e_hora = datetime.datetime(2024,4,5,19,30,15)
# Data e hora atual
agora = datetime.datetime.now()
print(agora.year) # Retorna o ano em inteiro, serve para mes, dia, hora, minutos e segundos
print(data,hora)
print(data_e_hora)| Strftime E Strptime
import datetime
data_e_hora_atual = datetime.datetime.now()
data_hora_formatada = data_e_hora_atual.strftime("Dia %d/%m/%Y, às %H horas e %M minutos")
print(data_hora_formatada)import datetime
texto = "aconteceu no dia 11-12-2022, às 14h e 30 min"
data_e_hora_2 = datetime.datetime.strptime(texto, "aconteceu no dia %d-%m-%Y, às %Hh e %M min")
print(data_e_hora_2)O metódo strptime(string Parse time) interpreta um texto convertendo em um datetime, basta reescrever o texto corretamente, e substituir a parte da data e hora pelo tempo.
locale
O módulo locale (biblioteca padrão python) é usada para configurar e gerenciar aspectos regionais e culturais do sistema, como formatação de números, datas, moedas e strings.
import locale
# Define o locale para o idioma e região desejados
locale.setlocale(locale.LC_ALL, 'pt_BR.UTF-8')
valor = 1234567.8923
# curency transforma em moeda local
print(locale.currency(valor, grouping=True)) # Saída: R$ 1.234.567,89
# Obter informações sobre o locale
print(locale.localeconv())Expressões Regulares (regex)
O re é um módulo da biblioteca padrão do Python. Ele é usado para trabalhar com expressões regulares, permitindo a busca, substituição e manipulação de padrões em strings. É basicamente uma forma de buscar valores/padrões dentro de um texto.
Raw strings (r"") são preferíveis quando você trabalha com regex, pois evitam a necessidade de escapar a barra invertida manualmente, tornando o código mais legível.
import re
# Busca expressões/textos (geralmente de uma lista de textos) que comecem com a letra E
padrao_inicial = '^E'
# Busca qualquer número de 0 a 9
padrao = '[0-9]'
# Busca dois números seguidos {2} de 0 a 9
padrao2 = '[0-9]{2}'
# Busca dois números em sequencia, seguidos de h
padrao3 = '[0-9]{2}h'
# Busca dois números no final do texto
padrao4 = '[0-9]{2}$'
# Busca uma palavra e mais UM caractere qualquer ( . )
padrao5 = 'dor.'
# Procura caracteres que sejam igual ao ultimo em sequencia até o fim.
padrao6 = 'on.*'
texto = "Estou aqui fazendo 9 embaixadinhas faz 5 horas"
# Encontra a primeira ocorrência do número recebendo o padrão e o texto
busca = re.search(padrao, texto)
# imprime o objeto com valor encontrado e o índice dele
print(busca) # Saída: <re.Match object; span=(19, 20), match='9'>
# Imprime valor encontrado
print(busca.group())
# Imprime o índice do inicio e fim do valor encontrado
print(busca.start(), busca.end())
# Substitui todas as ocorrências
texto_modificado = re.sub(r"embaixadinhas", "agachamentos", texto)
print(texto_modificado) # Saída: Estou aqui fazendo 9 agachamentos faz 5 horas
texto2 = "pedro dormiu ontem as 22 mas acordou as 05h30min"
# Retorna uma lista com todas as ocorrências
busca2 = re.findall('[0-9]{2}', texto2)
print(busca2) # Saída: ['22', '05', '30']A barra invertida, \ serve para escapar caracteres como o ponto (.). É case sensitive.
import re
texto = """
Nome: Marcos | Idade: 30| CPF: 012.345.678-90 | País de origem: Brasil
Nome: Ana | Idade: 28 |CPF: 098.765.432-10 | País de origem: Brasil
Nome: Isadora | Idade: Não informado | CPF: 090.080.070-65 | País de origem: Brasil
Nome: Guilherme| Idade: 21 | CPF: 111.222.333-45 | País de origem: Brasil
"""
padrao_cpf = r"[0-9]{3}\.[0-9]{3}\.[0-9]{3}-[0-9]{2}"
cpfs = re.findall(padrao_cpf, texto)
print(*(f"Cpf: {cpf}" for cpf in cpfs),sep="\n")import re
texto = """
A reunião está marcada para o dia 15/03/2023.
Lembre-se de entregar o relatório até 28/02/2023.
O evento acontecerá em 10/04/2023 no auditório principal.
"""
def ler_datas(texto):
padrao_data = r'[0-9]{2}/[0-9]{2}/[0-9]{4}'
datas = re.findall(padrao_data, texto)
# Desempacoto a lista e separo com quebra de linha
print(*datas,sep="\n")
ler_datas(texto)hashlib
O módulo hashlib é usado para calcular hashes criptográficos de dados. Ele fornece algoritmos como MD5, SHA-1, SHA-256, SHA-512, entre outros. Os hashes são funções que pegam uma entrada (por exemplo, uma string ou um arquivo) e geram um valor fixo, que é único para aquele conteúdo.
import hashlib
texto = "minha_senha_secreta"
hash_sha256 = hashlib.sha256(texto.encode()).hexdigest()
print(hash_sha256)
# EXEMPLO 2 sha256
import hashlib
algorithm = hashlib.sha256()
# retorna um hash de um estado inicial vazio, pois ainda não tem frase
print(algorithm.digest())
algorithm.update("Hello, World!".encode('utf-8'))
# retorna o hash em formato de string hexadecimal, com a frase inclusa
print(algorithm.hexdigest()) #posso usar o digesttexto.encode() → Converte a string em bytes. hashlib.sha256() → Cria um hash SHA-256. exdigest() → Retorna o hash em formato hexadecimal.
.hexdigest(): Hexadecimal: 91c748d7f46a8eecb7e5cc0b5d6c7484175dfbeb0247cb48a3a62bff0a5c2e44
.digest() → Retorna o hash como bytes brutos (mais compacto) Bytes: b'\x91\xc7H\xd7\xf4j\x8e\xec\xb7\xe5\xcc\x0b]l...'
collections
O módulo collections do Python fornece tipos de dados especializados e coleções de dados que podem ser mais eficientes e úteis do que os tipos de dados incorporados padrão, como listas, tuplas, dicionários e conjuntos.
namedtuple(): Cria tuplas nomeadas, que são como tuplas regulares, mas com campos nomeados, facilitando o acesso a cada valor. É uma maneira de criar pequenas classes para armazenar dados de forma mais legível.
deque() (Fila e Pilha): Um tipo de fila ou pilha eficiente. O deque (abreviação de "double-ended queue") permite inserções e remoções eficientes tanto no início quanto no final da lista. Diferentemente das listas, o deque é otimizado para adicionar/remover itens em ambas as extremidades.
O defaultdict do módulo collections é uma subclasse de dicionário do Python que fornece automaticamente um valor padrão para uma chave que ainda não existe — evitando erros de KeyError.
from collections import Counter, namedtuple, deque
from operator import itemgetter
from collections import defaultdict
lista_frutas_repetidas = ['morango','uva','pera','abacaxi','morango','banana', 'maçã', 'laranja', 'banana',
'laranja', 'banana', 'maçã']
# retorna um dicionario com as frutas e suas respectivas contagens
print(Counter(lista_frutas_repetidas))
# cria uma tupla nomeada
game = namedtuple('game',['nome', 'nota'])
game1 = game('God of War', 9.5)
game2 = game('The Last of Us', 9.8)
print(game1) # Saída: game(nome='God of War', nota=9.5)
print(game2) # Saída: game(nome='The Last of Us', nota=9.8)
# Ordenar dicionarios
dicionario = {'pedro': 22, 'maria': 25, 'joao': 30, 'ana': 20}
# Ordena por idade, indice 0 seria pela chave
print(sorted(dicionario.items(), key=itemgetter(1)))
# Utilizando deque
fila = deque([1, 2, 3])
fila.append(4) # Adiciona ao final
fila.appendleft(0) # Adiciona no início
print(fila) # Saída: deque([0, 1, 2, 3, 4])
fila.pop() # Remove do final
fila.popleft() # Remove do início
print(fila) # Saída: deque([1, 2, 3])
# exemplo com inteiros defaultdict
d = defaultdict(int) # o valor padrão para novas chaves será 0 (int())
d['a'] += 1
print(d['a']) # 1
# valor padrão é uma lista vazia (como a chave não existe será criada automaticamente).
listas = defaultdict(list)
listas['a'].append(1)
listas['a'].append(2)
print(listas) # {'a': [1, 2]}Exemplo que geraria erro no defaultdict: d = {} d['a'] += 1 # Erro! KeyError: 'a'.
pprint (pretty-print)
O módulo pprint (pretty-print) em Python serve para exibir dados de forma organizada e legível, especialmente estruturas complexas como dicionários e listas aninhadas.
import pprint
dados = {
"nome": "Alice",
"idade": 30,
"hobbies": ["ler", "programar", "viajar"],
"enderecos": [
{"cidade": "São Paulo", "pais": "Brasil"},
{"cidade": "Lisboa", "pais": "Portugal"}
]
}
pprint.pprint(dados)smtplib
smtplib é um módulo nativo do Python usado para enviar e-mails via o protocolo SMTP (Simple Mail Transfer Protocol). Ela permite que você se conecte a servidores de e-mail e envie mensagens de forma programática
| Host | Endereço |
|---|---|
| Gmail | smtp.gmail.com |
| Hotmail | smtp.live.com |
| Outlook | outlook.office365.com |
| Yahoo | smtp.mail.yahoo.com |
Atualmente para liberar conexão com aplicativos externos (como python) é necessário ativar verificação duas etapas e criar uma senha em Senhas de app, assim o código passado deve ser usado para se conectar com o gmail.
import smtplib
my_email = "verificadordeseguranca@gmail.com"
password = "qrnl evsy nwfj ucqo" # senha de aplicativo gerado na configuração do gmail.
with smtplib.SMTP("smtp.gmail.com", port=587) as connection:
connection.starttls() # torna a conexão segura com o protocolo TLS
connection.login(user=my_email, password=password)
# Envia o email com titulo e duas linhas para inserir o conteudo
connection.sendmail(from_addr=my_email, to_addrs="diogomamedio@yahoo.com.br", msg="subject:Hello\n\n It is a test")Assuntos Relacionados
HTTPServer
O módulo http.server no Python é um servidor HTTP embutido que permite servir arquivos e responder a requisições HTTP. Ele é útil para testes rápidos ou desenvolvimento local, sem precisar configurar servidores como Apache ou Nginx.
Iniciar Servidor Python HTTPServer
Vá ao diretório onde estão os arquivos que deseja compartilhar. Basta acessar o ip da maquina com a porta.
$ python -m http.server 8001 # Por padrão abre na porta 8000Assuntos Relacionados
Python Package Index (PyPI)
É um repositório de software para a linguagem de programação Python. Inumeras bibliotecas externas que podem ser importadas para ajudar a resolver diversos tipos de problemas.
Instalação Biblioteca para Tabela
Importação de uma biblioteca de tabela para terminal. Documentação completa no pypi.
$ python -m pip install -U prettytablefrom prettytable import PrettyTable
table = PrettyTable()
table.add_column("CARROS",
["Onix","Gol","HB20"])
table.add_column("MARCA",
["Chevrolet","Volkswagen","Hunday"])
print(table)Instalação Biblioteca para extração de cores
Colograma é uma biblioteca usada para extrar cores a partir de uma imagem.
$ pip install colorgram.pyimport colorgram
cores = []
cores_extraidas = colorgram.extract("extrair_cor_python.jpg",10)
for cor in cores_extraidas:
# Desempacotamento ao inves de chamar cada propriedade (r = cor.rgb.r, g = cor.rgb.g, b ...)
r, g, b = cor.rgb
cores.append((r,g,b))
print(cores)Api e Endpoints Python
APIs Web → Permitem a comunicação entre aplicações através da internet. Exemplo: APIs do Google Maps, OpenWeather, Twitter, etc. Tecnologias comuns: REST, SOAP, GraphQL. Frameworks populares: Flask, FastAPI, Django REST Framework.
Algumas APIs retornam textos com entidades HTML, então precisamos convertê-los para leitura humana. exemplo: < → representa < (menor que), e o unescaping é o processo de converter essas entidades de volta para seus caracteres normais. No python para resolver esse problema use o modulo html tem o metodo unescape().
Autenticação por cabeçalho (header authentication) é uma técnica comum em APIs onde as credenciais de acesso são enviadas no cabeçalho HTTP da requisição, em vez de no corpo da requisição ou na URL. Quando você faz uma requisição a uma API protegida, ela exige que você se identifique. O campo Authorization é um cabeçalho HTTP usado para autenticação. A API lê esse cabeçalho e permite ou nega o acesso.
TIPOS DE AUTENTICAÇÃO POR CABEÇALHO:
Baren Token: Você recebe esse token após fazer login ou se autenticar de alguma forma. Depois, envia ele no cabeçalho de cada requisição.
Api Key: Uma chave secreta que a API fornece a você para autenticar suas requisições.
Basic Auth: O cliente envia seu nome e senha codificados em Base64. Authorization: Basic base64(usuario:senha).
Instalar pacote request
$ pip install requestsimport requests
import html # Para usar o unescape
response = requests.get(url="http://api.open-notify.org/iss-now.json")
print(response) # Saída: <Response [200]>
print(f"{response.status_code}\n\n")
# Ao inves de tratar cada um dos status codes de forma individual, usar o método raise_for_satus
response.raise_for_status()
data = response.json() # Saída: {... 'iss_position': {'latitude': '-37.9362', 'longitude': '178.4000'}}
print(data)
# acessar cada um dos dados
print(response.json()["iss_position"], response.json()["iss_position"]["latitude"], sep="\n")
#--- API SUNRISE ---#
# site para localização latlong.net
MY_LAT = -12.081341
MY_LONG = -45.789700
# usar parametros obrigatórios conforme a documentação para fazer uma requisição
parameters = {
"lat": MY_LAT,
"lng": MY_LONG,
"formatted": 0, # mostra a data inteira com formato de 24horas
}
response = requests.get(url="https://api.sunrise-sunset.org/json", params=parameters)
response.raise_for_status()
data = response.json()
sunrise = html.unescape(data["results"]["sunrise"])
sunset = html.unescape(data["results"]["sunset"])
print(f"O Sol nasce: {sunrise}\nO Sol se põe: {sunset}")import requests
# URL base de exemplo (pode ser substituída por qualquer API REST real)
BASE_URL = "https://jsonplaceholder.typicode.com/posts"
# ========================
# MÉTODO GET
# ========================
# Recupera dados de um recurso existente (por exemplo, um post com ID 1)
response_get = requests.get(f"{BASE_URL}/1")
print("GET status:", response_get.status_code)
print("GET resposta:", response_get.json()) # Mostra o conteúdo da resposta em formato JSON
# ========================
# MÉTODO POST
# ========================
# Cria um novo recurso (post)
# O servidor geralmente retorna o novo recurso criado com um ID
new_post_data = {
"title": "Meu novo post",
"body": "Conteúdo do post",
"userId": 1
}
response_post = requests.post(BASE_URL, json=new_post_data)
print("\nPOST status:", response_post.status_code)
print("POST resposta:", response_post.json()) # Retorna um objeto python (dict, list, etc...)
print(f"TEXTOOOO: {response_post.text}") # Retorna o conteudo bruto como string
# ========================
# MÉTODO PUT
# ========================
# Atualiza completamente um recurso existente (substitui todos os campos)
update_post_data = {
"id": 1,
"title": "Post atualizado",
"body": "Novo conteúdo do post",
"userId": 1
}
response_put = requests.put(f"{BASE_URL}/1", json=update_post_data)
print("\nPUT status:", response_put.status_code)
print("PUT resposta:", response_put.json())
# ========================
# MÉTODO PATCH (atualização parcial)
# ========================
# Atualiza parcialmente um recurso (ex: apenas o título)
partial_update_data = {
"title": "Título alterado apenas"
}
response_patch = requests.patch(f"{BASE_URL}/1", json=partial_update_data)
print("\nPATCH status:", response_patch.status_code)
print("PATCH resposta:", response_patch.json())
# ========================
# MÉTODO DELETE
# ========================
# Remove um recurso (por exemplo, o post com ID 1)
response_delete = requests.delete(f"{BASE_URL}/1")
print("\nDELETE status:", response_delete.status_code)
print("DELETE resposta:", response_delete.text) # Geralmente vazio ou com mensagemimport requests
# Token Bearer (o mais comum em APIs REST)
headers = {
"Authorization": "Bearer SEU_TOKEN_AQUI"
}
response = requests.get("https://api.exemplo.com/dados", headers=headers)
# Chave de API (API Key)
headers = {
"x-api-key": "SUA_CHAVE_API"
}
response = requests.get("https://api.exemplo.com/dados", headers=headers)
# Basic Auth (usuário e senha codificados em base64)
from requests.auth import HTTPBasicAuth
response = requests.get("https://api.exemplo.com/dados", auth=HTTPBasicAuth("usuario", "senha"))Exemplos de autenticação por cabeçalho.
Assuntos Relacionados
nympy
A biblioteca NumPy (Numerical Python) é uma biblioteca externa do Python usada para trabalhar com arrays e operações matemáticas eficientes. Ela é muito mais rápida do que listas comuns do Python porque usa arrays otimizados e operações vetorizadas.
import numpy as np
lista = [1, 2, 3, 4, 5]
array = np.array([1, 2, 3, 4, 5])
# Multiplicação na lista -> Repete os elementos
print(lista * 2)
# Saída: [1, 2, 3, 4, 5, 1, 2, 3, 4, 5]
# Multiplicação no NumPy -> Faz a operação nos elementos
print(array * 2)
# Saída: [ 2 4 6 8 10]
# -- Operações matemáticas rápidas
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
print(a + b) # [5 7 9]
print(a * b) # [4 10 18]
print(np.mean(a)) # Média: 2.0
print(np.sum(a)) # Soma: 6
print(np.sqrt(a)) # Raiz quadrada: [1. 1.41 1.73]Faker
O pacote Faker é uma ferramenta muito útil em Python para gerar dados falsos (fake data) de forma rápida e automatizada. Ela é amplamente usada em testes, prototipagem e desenvolvimento, principalmente quando você precisa preencher um banco de dados com informações realistas, mas não reais.
Instale com o pip.
from faker import Faker
faker = Faker('pt_BR')
print(faker.name()) # Nome completo em português
print(faker.email()) # Email
print(faker.address()) # Endereço
print(faker.cpf()) # CPF válido
print(faker.date_of_birth()) # Data de nascimento