AI (Inteligencia Artificial)
Inteligência Artificial é o campo da computação que cria sistemas capazes de simular comportamentos inteligentes humanos, como aprender, raciocinar, resolver problemas, reconhecer padrões, entender linguagem natural e tomar decisões.
Esses sistemas não são "inteligentes" como seres humanos, mas podem realizar tarefas específicas de forma eficiente, geralmente com base em dados.
| Termo | Explicação rápida |
|---|---|
| IA | Área geral que busca simular a inteligência humana |
| Machine Learning | Subcampo da IA: o sistema aprende com dados, sem ser programado explicitamente |
| Deep Learning | Subcampo do ML: usa redes neurais profundas para lidar com grandes volumes de dados |
IA forte teria consciência própria, capacidade de raciocinar, tomar decisões gerais e aprender como um ser humano.
| Tipo de IA | Também chamada de... | Características principais | Exemplo atual |
|---|---|---|---|
| IA Fraca | IA estreita (Narrow AI) | Projetada para realizar uma única tarefa específica | Reconhecimento facial do celular, Assistentes virtuais (Siri, Alexa), filtros de spam, recomendações de filmes |
| IA Forte | IA geral (AGI – Artificial General Intelligence) | Capaz de aprender e executar qualquer tarefa cognitiva humana | Ainda não existe |
Redes neurais são modelos computacionais inspirados no cérebro humano, usados em inteligência artificial e aprendizado de máquina para reconhecer padrões, tomar decisões e aprender com dados.
Uma rede neural é um conjunto de "neurônios artificiais" organizados em camadas. Cada neurônio:
-
Recebe entradas (números),
-
Faz uma conta simples com esses dados (multiplica, soma, aplica uma função),
-
E passa a saída para os próximos neurônios.
Rede neural: Detectar emoções em voz ou rosto, traduzir texto em tempo real, gerar imagens. Modelo não neural (Classico): Prever o preço de um imóvel com base em metragem e localização (regressão linear).
| Aspecto | Redes Neurais | Modelos Classicos |
|---|---|---|
| Inspiração | Funcionamento do cérebro humano | Estatística e regras matemáticas claras |
| Capacidade de aprendizado | Aprendem representações complexas e não lineares | Melhor em dados simples ou lineares |
| Exemplo de modelo | Redes Neurais Artificiais (ANNs, CNNs, RNNs) | Regressão linear, árvore de decisão, SVM |
| Requisitos de dados | Precisam de grandes volumes de dados | Podem funcionar bem com dados menores |
| Interpretação | Difícil de interpretar (caixa preta) | Mais interpretáveis |
| Custo computacional | Alto (precisam de GPU muitas vezes) | Baixo ou moderado |
Os parâmetros de um modelo são valores numéricos (pesos) que o modelo aprende durante o treinamento. Eles funcionam como "memória" do modelo — é onde estão gravadas as relações que ele aprendeu.
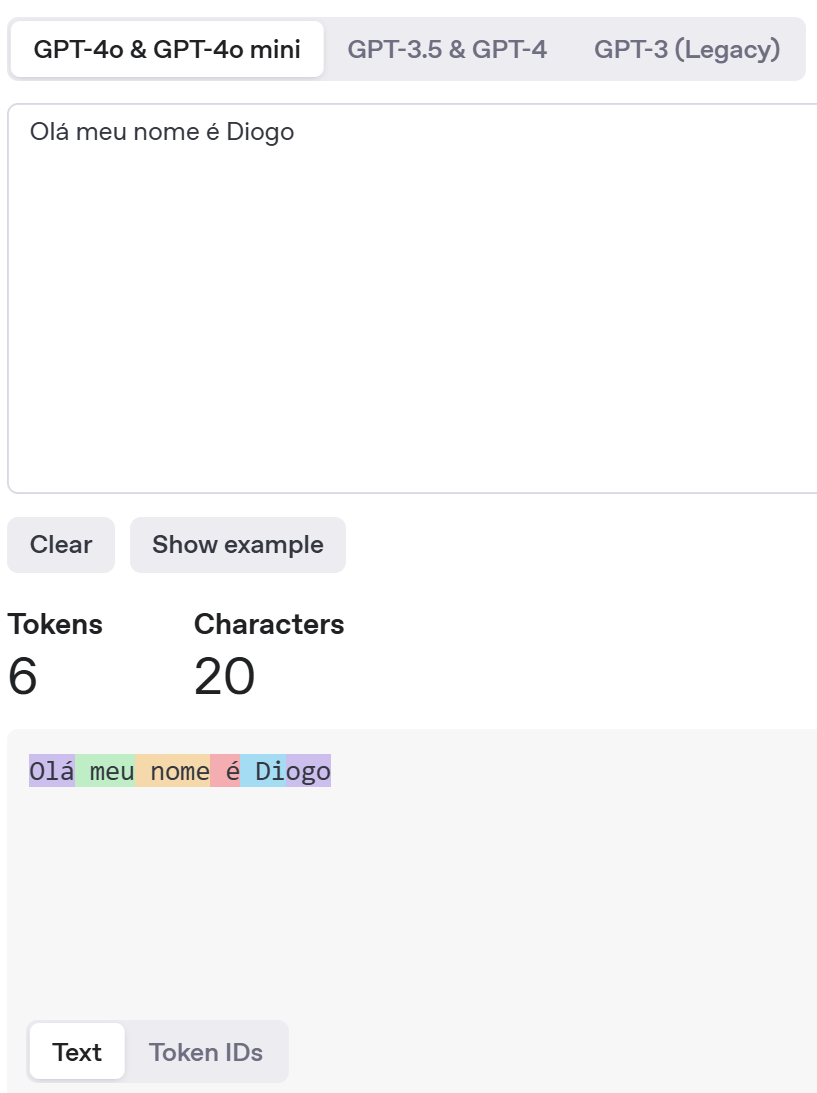
Um tokenizador (ou tokenizer, em inglês) é uma ferramenta que divide o texto em partes menores chamadas de “tokens”, que podem ser palavras, pedaços de palavras ou até caracteres. Esses tokens são como a forma que um modelo de IA entende o texto. Ele não entende frases diretamente como humanos — primeiro o texto precisa ser quebrado e transformado em números (vetores), e o tokenizador faz essa primeira parte.
No exempo abaixo temos 6 tokens (pintados de cores diferentes), e o token id é um array com esses numeros: [89191, 18477, 16667, 1212, 9196, 16335]
Redes Neurais
O Perceptron é o modelo mais simples de rede neural artificial. Ele foi criado na década de 1950 por Frank Rosenblatt e é considerado o "bloco básico" das redes neurais modernas. Ele simula um neurônio. Recebe entradas, multiplica cada uma por um peso, soma tudo e aplica uma função de ativação para decidir a saída (por exemplo, 0 ou 1).
O Perceptron pode ser usado para problemas como:
-
Determinar se um e-mail é spam ou não.
-
Classificar imagens simples (como dígitos 0 ou 1).
-
Verificar se um aluno passou ou reprovou com base em nota e presença.
TensorFlow e PyTorch
São ferramentas (ou bibliotecas de código) que ajudam programadores a criar, treinar e executar modelos de machine learning e deep learning., principalmente redes neurais.
-
TensorFlow foi criado pelo Google.
-
PyTorch foi criado pelo Facebook (Meta).
-
Ambos fazem cálculos matemáticos complexos que são necessários para que a IA funcione.
| Termo | O que é? |
|---|---|
| PyTorch / TensorFlow | Bibliotecas para desenvolver e treinar modelos de IA |
| GPT | Modelo de linguagem baseado em Transformers |
| ChatGPT | Aplicação que usa o GPT para gerar respostas em linguagem natural |
Comandos Instalação Pytorch e TensorFlow
Veja a versão da CUDA (cuda: é a plataforma da NVIDIA para rodar cálculos na GPU) no site do Pytorch, após descobrir qual versão cuda da sua placa de video, selecione as configurações, que o comando será gerado:
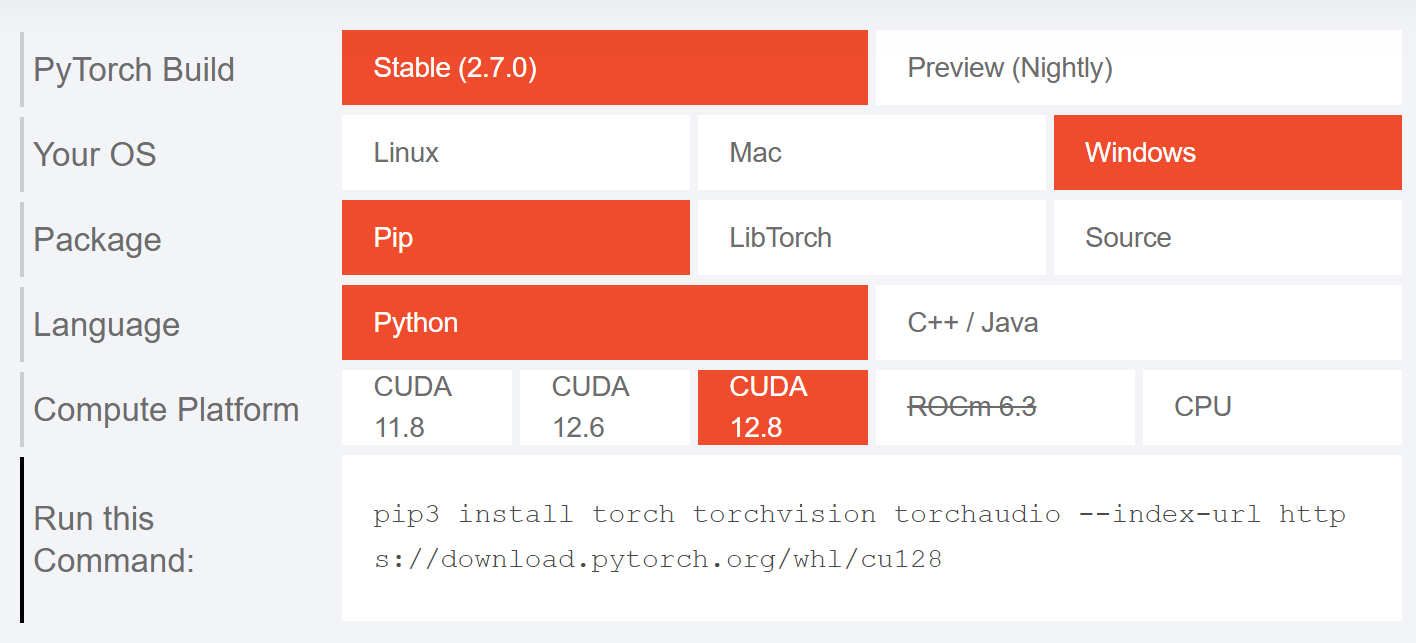
$ nvidia-smi # no prompt irá mostrar a versão da placa e o CUDA
$ pip install torch # Instala sem usar os recursos da placa de video.
$ pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128 # instala para usar a GPU
$ pip install tensorflowTransformers
Transformers são um tipo especial de modelo de inteligência artificial criado para entender e gerar linguagem humana (texto). É como um cérebro digital que aprendeu a ler, escrever, traduzir e responder perguntas, baseado em muitos e muitos textos. Esse modelo aprendeu a "prestar atenção" nas partes importantes de uma frase. E isso ajudou a IA a entender melhor o que as palavras realmente querem dizer em diferentes contextos.
A biblioteca mais famosa para usar transformers (biblioteca externa) é a do Hugging Face. Os modelos são salvos na pasta do S.O. Windows: C:\Users\Diogo<Seu usuário>\.cache\huggingface\hub. Linux: ~/.cache/huggingface/transformers.
from transformers import pipeline
# Cria um modelo já pronto para analisar sentimentos
modelo = pipeline("sentiment-analysis") # passo a tarefa que quero para o pipeline
# Testa com um texto
print(modelo("I felling bad")) # saída: [{'label': 'NEGATIVE', 'score': 0.9997599720954895}]
modelo2 = pipeline("fill-mask")
print(modelo2("The capital of <mask> is Brasilia")[0]['sequence']) # retorna uma lista com dicionário que contém a chave sequence
# OUTRO EXEMPLO COM 3 MODELOS
modelos = [
{
# Modelo generico
'nome': 'FacebookAI/xlm-roberta-base',
'token': '<mask>'
},
{
# Modelo em português
'nome': 'neuralmind/bert-base-portuguese-cased',
'token': '[MASK]'
},
{
# Modelo treinado na area Juridica
'nome': 'rufimelo/Legal-BERTimbau-base',
'token': '[MASK]'
}
]
for dict_modelo in modelos:
nome_modelo = dict_modelo['nome']
token_modelo = dict_modelo['token']
print(f"Teste modelo: {nome_modelo}")
modelo = pipeline("fill-mask",model=nome_modelo)
frase = f"Este documento é essencial para a {token_modelo}."
predicoes = modelo(frase)
for predicao in predicoes:
resposta = predicao['token_str']
score = predicao['score'] * 100
frase = predicao['sequence']
print(f"Predição: {resposta} com score de: {score:.2f}% -> '{frase}' ")
input("Pressione qualquer tecla para ir para o proximo modelo")pipeline é uma função pronta que te dá acesso rápido a modelos de inteligência artificial sem você precisar configurar tudo manualmente. Ela automaticamente já "tokeniza" as palavras (transforma em numeros para o computador) e vice-versa.
modelo = pipeline("sentiment-analysis")
-
Baixa automaticamente um modelo de IA (por padrão, treinado em inglês).
-
Carrega o modelo com todos os parâmetros corretos.
-
Prepara uma função que você pode usar direto pra analisar textos.
obs.: Você não está passando um modelo diretamente. Está dizendo: "Quero usar um modelo pré-treinado para análise de sentimentos." e ele escolhe um modelo automaticamente.
# Importa a função 'pipeline' da biblioteca transformers, que cria uma interface simples para usar modelos de IA já prontos
from transformers import pipeline
# Cria um pipeline do tipo "text-generation" (geração de texto)
# Usa um modelo específico hospedado na Hugging Face: "Felladrin/Llama-68M-Chat-v1"
# max_new_tokens define o máximo de palavras que o modelo pode gerar
# penalty_alpha e top_k são ajustes que controlam a criatividade e a variedade das respostas
chatbot = pipeline(
"text-generation",
model="Felladrin/Llama-68M-Chat-v1",
max_new_tokens=300, # máximo de 300 palavras geradas
penalty_alpha=0.5, # penalidade para evitar repetições
top_k=4, # considera as 4 melhores opções de palavras ao escolher a próxima
)
# OBSERVAÇÃO:
# A mensagem para o modelo precisa seguir um formato especial com marcações como <|im_start|>, <|im_end|> e os papéis (system, user, assistant)
# Define a mensagem do "sistema", ou seja, instruções para o modelo sobre como se comportar
mensagem_sistema = 'You are a helpful artificial intelligence assistant.'
# Cria a parte do prompt correspondente à mensagem do sistema
prompt_sistema = f'<|im_start|>system\n{mensagem_sistema}<|im_end|>\n'
# Define o que o usuário quer perguntar
mensagem_usuario = 'How can I become a Python programmer?'
print('Sua pergunta: ', mensagem_usuario)
# Cria a parte do prompt correspondente à mensagem do usuário
prompt_usuario = f'<|im_start|>user\n{mensagem_usuario}<|im_end|>\n'
# Junta as duas partes do prompt e adiciona a marcação que indica que o assistente deve responder
conversa = f'{prompt_sistema}{prompt_usuario}<|im_start|>assistant\n'
# Exibe o prompt completo que será enviado ao modelo
print(conversa)
# Envia o prompt para o modelo gerar a resposta
resposta = chatbot(conversa)
# Exibe o resultado bruto gerado pelo modelo (em forma de dicionário)
print(resposta)
# Mostra o texto completo gerado, que inclui o prompt e a resposta do bot
print(resposta[0]['generated_text'])
# Separa e limpa apenas a parte da resposta gerada pelo assistente
resposta_formatada = resposta[0]['generated_text'].split('<|im_start|>assistant\n')[-1].rstrip('<|im_end|>')
# Exibe a resposta final, limpa
print('Resposta do bot: ', resposta_formatada)
# A partir daqui, entra em um loop onde você pode continuar perguntando ao chatbot
# Começa a conversa com a mensagem do sistema (mantendo o contexto do assistente)
conversa = mensagem_sistema
# Loop para interação contínua com o chatbot
while True:
# Pede uma nova pergunta ao usuário
mensagem_usuario = input('Escreva sua pergunta (em inglês): ')
# Adiciona a pergunta e a marcação que indica que o assistente deve responder
conversa += f'<|im_start|>user\n{mensagem_usuario}<|im_end|>\n<|im_start|>assistant'
# Gera uma nova resposta do chatbot com base na conversa até o momento
resposta = chatbot(conversa)
# Atualiza a conversa com o texto completo gerado
conversa = resposta[0]['generated_text']
# Extrai somente a resposta do assistente, limpa
resposta_formatada = conversa.split('<|im_start|>assistant\n')[-1].rstrip('<|im_end|>')
# Exibe a resposta
print(f'Resposta do bot: {resposta_formatada}')from transformers import pipeline
modelo = "facebook/mbart-large-50-many-to-many-mmt"
mensagens = [
"Olá, mundo! Como posso ajudar você hoje?",
"Eu gostaria de saber mais sobre o mundo.",
"Obrigado por me ajudar!",
]
linguas = ["en_XX", "fr_XX", "es_XX"]
tradutor = pipeline(task="translation", model=modelo)
for lingua in linguas:
print(f"Tradução para {lingua}")
traducoes = tradutor(mensagens, src_lang="pt_XX", tgt_lang=lingua)
for mensagem, traducao in zip(mensagens, traducoes):
print(f"{mensagem} -> {traducao['translation_text']}")
print()Inference API
A Inference API (API de Inferência) é um serviço oferecido por plataformas como a Hugging Face, Groq e etc, que permite usar modelos de IA prontos diretamente pela internet, sem precisar baixar ou rodar nada localmente.
-
Treinamento = quando o modelo aprende (fase pesada, feita por quem cria o modelo).
-
Inferência = quando você usa um modelo treinado para fazer previsões ou gerar respostas.
Login cli huggingface
$ huggingface-cli login # Alguns modelos é necessário fazer login no terminal para usa-los. Coloque seu token.# Importa a biblioteca 'requests', usada para fazer requisições HTTP.
import requests
# Define o nome do modelo da Hugging Face que será utilizado para inferência.
modelo = 'mistralai/Mixtral-8x7B-Instruct-v0.1'
# Monta a URL da API da Hugging Face com base no nome do modelo.
url = f"https://api-inference.huggingface.co/models/{modelo}"
# Define o cabeçalho HTTP com o token de autenticação da Hugging Face.
headers = {"Authorization": f"Bearer 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"}
# Cria o corpo (payload) da requisição em formato JSON.
json = {
'inputs': 'Hello, what is your name?', # Prompt de entrada enviado ao modelo.
'options': {'use_cache': False, 'wait_for_model': True}, # Opções: não usar cache e esperar o modelo carregar se necessário.
}
# Envia a requisição POST para a API da Hugging Face com o JSON e os headers.
response = requests.post(url, json=json, headers=headers)
# Imprime o objeto da resposta HTTP (pode mostrar status code e outras informações).
print(response)
# Imprime o conteúdo da resposta convertida em JSON (normalmente é a resposta do modelo).
print(response.json())# Importa a classe AutoTokenizer da biblioteca transformers para lidar com tokenização.
from transformers import AutoTokenizer
# Define um histórico de mensagens no formato de chat. Cada item é um dicionário com o papel ("role") e o conteúdo ("content"). cada resposta é adicionado a esse dicionário para que fique o histórico.
chat = [
{"role": "user", "content": "Olá, qual o seu nome?"},
{"role": "assistant", "content": "Olá, eu sou um modelo de AI. Como posso ajudar?"},
{"role": "user", "content": "Gostaria de aprender Python. Você tem alguma dica?"},
]
# Cria um tokenizador com base no modelo Mixtral da Hugging Face.
tokenizer_mixtral = AutoTokenizer.from_pretrained('mistralai/Mixtral-8x7B-Instruct-v0.1')
# Aplica o template de chat no formato esperado pelo modelo (sem tokenizar, apenas texto).
# 'add_generation_prompt=True' adiciona a instrução final para o modelo gerar uma resposta.
template_mixtral = tokenizer_mixtral.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
# Imprime o texto formatado para ser usado com o modelo Mixtral.
print('----- Chat formatado para modelo Mixtral -----')
print(template_mixtral)
# Usa outro tokenizador, desta vez para o modelo LLaMA pequeno (Felladrin).
tokenizer_llama = AutoTokenizer.from_pretrained("Felladrin/Llama-68M-Chat-v1")
# Aplica o mesmo template de chat, agora usando o formato esperado pelo modelo LLaMA.
template_llama = tokenizer_llama.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
# Imprime o template formatado para o modelo LLaMA.
print('----- Chat formatado para modelo Llama -----')
print(template_llama)
# Importa novamente a biblioteca requests para envio de requisições HTTP.
import requests
# Importa o AutoTokenizer para preparar o input no formato correto.
from transformers import AutoTokenizer
# Define o nome do modelo a ser usado.
modelo = 'mistralai/Mixtral-8x7B-Instruct-v0.1'
# Cria uma conversa simples com apenas uma pergunta do usuário.
chat = [
{"role": "user", "content": "Hello, what is your name?"},
]
# Cria o tokenizador apropriado para o modelo especificado.
tokenizer = AutoTokenizer.from_pretrained(modelo)
# Aplica o template de chat ao conteúdo, transformando-o no formato que o modelo espera.
chat_str = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
# Monta novamente a URL da API para o modelo.
url = f"https://api-inference.huggingface.co/models/{modelo}"
# Cria o JSON com o prompt formatado, sem cache, e esperando o modelo carregar.
json = {
'inputs': chat_str,
'options': {'use_cache': False, 'wait_for_model': True},
}
# Envia a requisição à API da Hugging Face.
response = requests.post(url, json=json)
# Imprime a resposta do modelo (já no formato JSON).
print(response.json())
# Importa as bibliotecas novamente.
import requests
from transformers import AutoTokenizer
# Define o modelo a ser usado.
modelo = 'mistralai/Mixtral-8x7B-Instruct-v0.1'
# Carrega o tokenizador correspondente ao modelo.
tokenizer = AutoTokenizer.from_pretrained(modelo)
# Cria a URL da API para o modelo.
url = f"https://api-inference.huggingface.co/models/{modelo}"
# Inicializa a conversa como uma lista vazia de mensagens.
chat = []
# Inicia um loop infinito para simular um chatbot interativo.
while True:
# Solicita uma mensagem do usuário.
mensagem = input('Faça sua pergunta em inglês ("q" para sair):')
# Encerra o loop se o usuário digitar 'q'.
if mensagem == 'q':
break
# Adiciona a mensagem do usuário à conversa.
chat.append({'role': 'user', 'content': mensagem})
# Formata a conversa completa no template do modelo.
chat_str = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
# Define os parâmetros para a geração da resposta.
json = {
'inputs': chat_str, # Texto formatado a ser enviado.
'parameters': {'max_new_tokens': 1_000}, # Limite de tokens gerados na resposta.
'options': {'use_cache': False, 'wait_for_model': True}, # Sem cache e aguardar carregamento do modelo.
}
# Envia a requisição POST e converte diretamente a resposta em JSON.
response = requests.post(url, json=json).json()
# Extrai o texto da resposta gerada, isolando apenas a parte da resposta.
mensagem_chatbot = response[0]['generated_text'].split('[/INST]')[-1]
# Mostra a resposta do chatbot ao usuário.
print('Resposta do chatbot:', mensagem_chatbot)
# Adiciona a resposta do chatbot ao histórico de mensagens.
chat.append({'role': 'assistant', 'content': mensagem_chatbot})
# Exibe o histórico final da conversa.
print(chat)O chat é basicamente um histórico simulado da conversa — uma representação explícita de tudo o que foi dito entre o usuário e o assistente até o momento.
import os
import requests
import dotenv
import streamlit as st
from transformers import AutoTokenizer
dotenv.load_dotenv()
token = os.getenv('TOKEN_HF')
# Dicionário com os modelos e tokens especiais de formatação de prompt usados por esses modelos.
# Esses modelos são text-generation. obs.: Existe limite de uso no hugging Face para inferences.
modelos = {
'mistralai/Mixtral-8x7B-Instruct-v0.1':'[/INST]',
'google/gemma-7b-it': '<start_of_turn>model\n',
}
modelo = st.selectbox("Selecione um modelo", options=modelos)
token_modelo = modelos[modelo]
st.write(f"Modelo selecionado: {modelo}")
st.write(f"Token de formatação do modelo no Hugging Face: {token_modelo}")
st.write(f"Meu token no Hugging Face: {token}")
if 'modelo_atual' not in st.session_state or st.session_state['modelo_atual'] != modelo: # primeira execuação do programa
st.session_state['modelo_atual'] = modelo
st.session_state['mensagens'] = []
nome_modelo= st.session_state['modelo_atual']
tokenizer = AutoTokenizer.from_pretrained(nome_modelo)
url = f'https://api-inference.huggingface.co/models/{nome_modelo}'
mensagens = st.session_state['mensagens']
# CHAT
area_chat = st.empty()
pergunta_usuario = st.chat_input("Digite sua pergunta: ")
if pergunta_usuario:
mensagens.append({"role": "user", "content": pergunta_usuario})
template = tokenizer.apply_chat_template(mensagens, tokenizer=False, add_generation_prompt=True)
json = {
'inputs': template,
'parameters': {'max_new_tokens': 1024},
'options': {'use_cache': False, 'wait_for_model': True}
}
headers = {"Authorization": f"Bearer {token}"}
response = requests.post(url, json=json, headers=headers).json()
print(response)
mensagem_chatbot = response[0]['generated_text'].split(token_modelo)[-1]
mensagens.append({"role": "assistant", "content": mensagem_chatbot})
with area_chat.container():
for mensagem in mensagens:
chat = st.chat_message(mensagem['role'])
chat.markdown(mensagem['content'])
print(mensagens)Antes de tudo, crie uma conta groq e gere uma api key, para usar com a biblioteca langchain.
import os
from langchain_groq import ChatGroq
api_key = "SUA_KEY_AQUI_BWxPolKn8CvJFM6XSBsWGdyb3FYExI"
os.environ["GROQ_API_KEY"] = api_key
chat = ChatGroq(model="meta-llama/llama-4-scout-17b-16e-instruct")
resposta = chat.invoke("Olá, Quem é você?")
print(resposta.content)Assuntos Relacionados
Datasets
Um dataset (ou conjunto de dados) é uma coleção organizada de dados usada para análise, pesquisa e treinamento de modelos de inteligência artificial (IA). Geralmente, um dataset é organizado em linhas e colunas, onde cada linha representa um registro e cada coluna representa uma característica ou atributo desse registro. Os datasets podem ser encontrados em diversos formatos, como planilhas Excel (XLS), arquivos CSV, TXT, JSON ou XML. No hugging face a biblioteca (externa - instalada com pip) usada é datasets. os arquivos ficam salvos no mesmo local dos modelos baixados com a biblioteca transformers (C:\Users\Diogo\.cache\huggingface\hub)
from datasets import load_dataset
dataset = load_dataset("imdb", streaming=True) # carregando o dataset do IMDb
print(dataset)
# resultado (label 0 é negativo e label 1 é positivo):
'''
DatasetDict({
# parte usada para treinamento do nosso modelo
train: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
# parte usada para validação do nosso modelo
test: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
# parte usada para gerar dados não supervisionados, ou seja, dados que não são usados para treinar o nosso modelo
unsupervised: Dataset({
features: ['text', 'label'],
num_rows: 50000
})
})
'''
dataset_treino = dataset['train'] # selecionando apenas a parte de treinamento do dataset
# print(dataset_treino)
# Iterando sobre os dados do dataset, sem precisar carregar tudo na RAM, por causa do streaming=True.
for linha in dataset_treino:
print(linha) # exibindo cada linha do dataset
input()
print(dataset_treino[9]) # exibindo o resultado da posição 9 das 250.000 linhas do dataset_treino
input()
print(dataset_treino[9]['text']) # exibindo apenas o texto da posição 9
input()
print(dataset_treino[9]['label']) # exibindo a classe (positivo ou negativo) da mensagem
df = dataset_treino.to_pandas() # convertendo o dataset para um DataFrame pandas
print(df) # exibindo todas as linhas do DataFrameO argumento streaming=True permite que o dataset seja carregado em tempo real, sem precisar carregar todo o conjunto de dados ao mesmo tempo na RAM. Isso é útil para grandes datasets ou quando você está trabalhando com dados que estão sendo atualizados constantemente.
from datasets import load_dataset
dataset = load_dataset('ashraq/esc50')
dados = dataset['train']
# carrega as 10 primeiras linhas para a memória
primeiras_linhas = dados.select(range(10))
# Carrega apenas uma amostra de som
dados_cachorro = dataset['train'][0] # nesse caso o 0 é dog
''' {'filename': '1-100032-A-0.wav', 'fold': 1, 'target': 0, 'category': 'dog', 'esc10': True, 'src_file': 100032, 'take': 'A', 'audio': {'path': None, 'array': array([0., 0., 0., ..., 0., 0., 0.], shape=(220500,)), 'sampling_rate': 44100}} '''O método .select() é uma forma eficiente de escolher subconjuntos de dados de um dataset do Hugging Face. Ele não carrega todo o dataset na memória, o que o torna ideal para testes, amostragem, ou debug.
Nos dados do audio, em cada captura feita pelo microfone, é gerado um número do vetor que observamos na saída.
-
array: é um array NumPy contendo os valores das amostras do áudio (representando o som). No print sai encurtado! -
shape=(220500,): significa que o áudio tem 220.500 amostras. -
sampling_rate=44100: são 44.100 amostras por segundo, ou seja, o áudio tem 5 segundos de duração (220500 / 44100 = 5).
Engenharia de prompt
- Generico demais: Faça um plano de aula sobre música.
- Clareza: Sou um professor de música para crianças, faça um plano de aula sobre música.
- Especificidade: Sou um professor de música para crianças, faça um plano de aula sobre música, onde a turma tem 4 alunos e uma aula por semana de guitarra, essa é a primeira aula com duração de 1 hora, tenho projetor, notebook e duas guitarras.
Os 4 principais elementos de um bom prompt são: Contexto, Instrução, Dados de entrada (são mutaveis) e Indicador de Saída ( indica que a partir dali quer uma resposta, fica no final do prompt. ex.: "resposta: ")
Persona: Utilizar uma persona é uma ótima forma de criar um contexto para o seu prompt. A ideia por trás é utilizarmos uma pessoa, fictícia ou real, para nos comunicarmos com o modelo. Ex.: "Escreva uma historia de magia estilo j.k. rowling" ou "Escreva um poema ao estilo de um poeta do romantismo brasileiro".
Delimitadores: Dar enfase aos trechos mais importantes no prompt, elementos que não podem passar despercebidos pelo modelo. Podemos utilizar diversos delimitadores, como ####, """, --, etc. As quatros cerquilas pode ser recomendada por gastar apenas um token.
Saídas estruturadas: Indica ao modelo como ele deve dar a resposta (excelente para uso de em uma api que espera uma resposta exata). ex.: Qual o nome dos jogadores do Chelsea? retorne a resposta no formato de uma lista python.
COT (chain of thought - cadeia de pensamento): Aumentar o tempo de raciocinio para o modelo ser mais acertivo. Colocando no prompt a frase: "Elabore primeiro sua solução para o problema e compare/verifique se está correta".
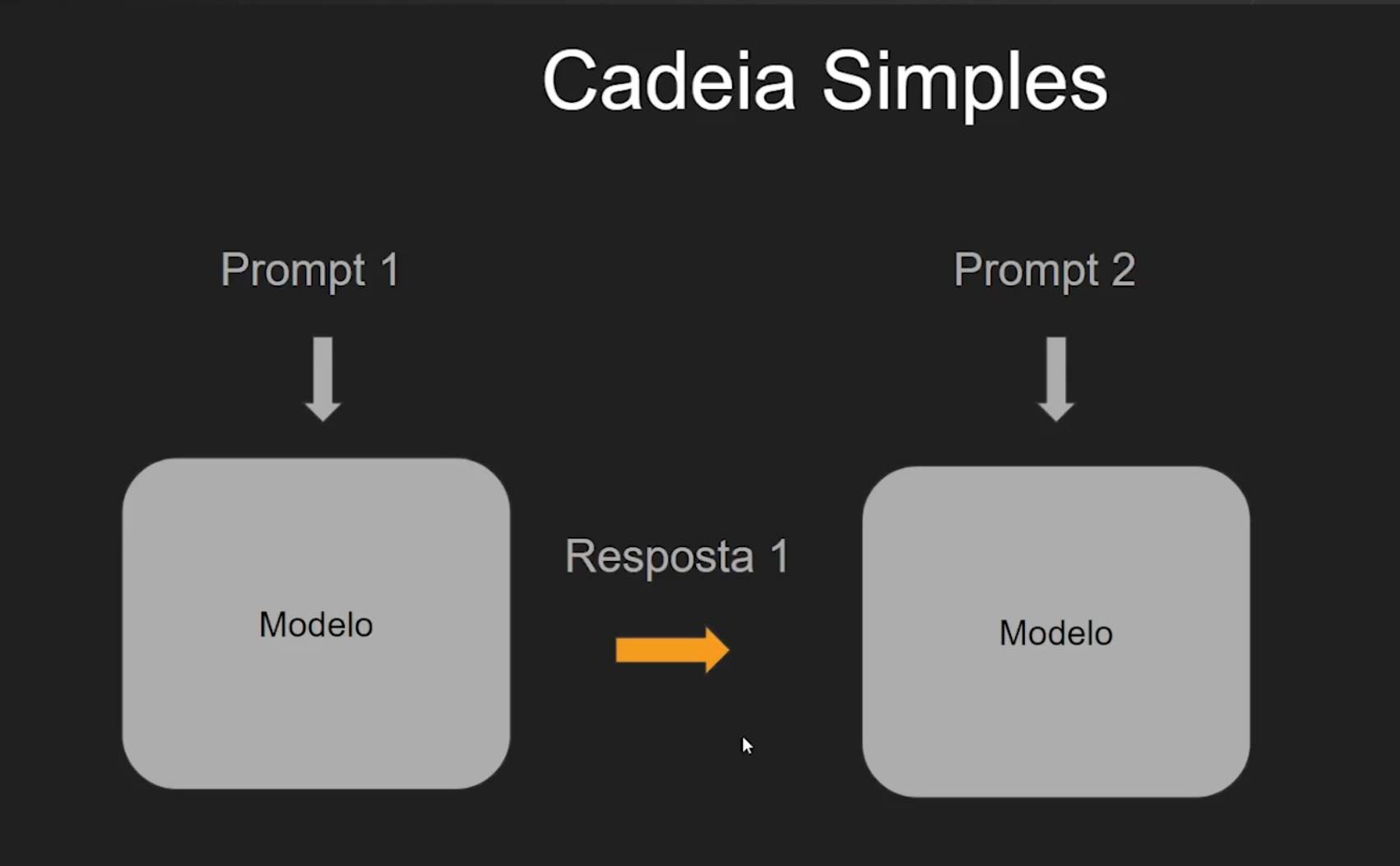
Encadeamento (Chaining): Dividir para conquistar, divida o prompt em varias partes para que ele execute uma coisa de cada vez: